
プログラミングって何ができるの?実生活に役立つアプリを作りたい!ということで、以前、実践例の紹介として、ボートレース予想AIをranking学習で実装しました。
前回はボートレース予想AIをランキング学習で作ってみましたが、新しい予想方法として運用していく目処が立ったので、その成果を実装コードを交えて紹介していきます。
ボートレースが好きな方、プログラミングの初心者の方にも興味を持っていただける内容だと思うので、ぜひお付き合いください。
前回の振り返り|lightGBM編
まずは前回のモデルの振り返りをサクッと振り返っていきます。詳しく知りたい方はこちらのランキング学習を読んでいただければと思います。
採用したアルゴリズム
前回のAIでは各選手の力関係・実力を評価したいという目的があったので、ランキング学習なる手法を採用しました。
ランキング学習とは?AIの判断力を鍛える新技術
ランキング学習(Learning to Rank)は、AIが「順位付け」の能力を習得するための機械学習手法です。この技術は、検索エンジンの結果を最適化するために広く用いられていますが、近年では金融やスポーツ予測など、さまざまな分野で活用が進んでいます。
具体的には、複数のデータポイントの中から適切な順序を見つけ出すタスクに特化しています。例えば、ボートレースにおいては、各選手の過去の成績、天候条件、スタートタイミングなどの要素を基に、レース結果の「順位予測」を行うことが可能です。
実装を振り返る:ランキング学習を活用した理由
記事で取り上げたボートレースAIでは、従来の分類問題や回帰問題では得られなかった精度向上を目指すため、ランキング学習を採用しました。この選択にはいくつかの理由があります。
- 順位予測に特化しているため
一般的な回帰分析では、選手ごとの「勝率」や「得点率」を個別に予測しますが、レース結果の順位全体を正確に捉えるには不十分です。ランキング学習なら、順位そのものをターゲットに学習できるため、より実用的な予測が可能になります。 - 特定の要素の重み付けがしやすい
ランキング学習では、各特徴量が順位付けに与える影響を直接反映できます。ボートレースでは、「スタートタイミング」のような一部の要素が勝敗に直結することが多いため、この特性は非常に有効です。 - 汎用性の高さ
一度ランキングモデルを構築すれば、他のスポーツや異なるデータセットへの応用も容易です。これは、長期的なプロジェクトの拡張性を考える上で大きなメリットとなります。
あとは単純にランキング学習を取り入れているモデルが少なかったので、試しにやってみようというのもありました。
ランキング学習での検証結果
以下は、以前のランキング学習モデルで予測したレースの的中率と回収率になります。
- 購入レース数:737レース
- 的中レース数:181レース
- 的中率:24.5%
- 回収率:89.6%
特徴量の工夫やパラメーターの調整など改善の余地はありそうでしたが、概ね納得の結果となりました。詳しい評価指数、特徴量については以前の記事を参考にしてください。
今回の予測手法は【XGboost】の分類
ということで本題に入ります。
まず今回の予測の手法はXGboostの勾配ブースティングを使っていくことにします。勾配ブースティング自体は多くの競馬・競艇AIの予測に使われていて、今更感はありますが、前回のモデルで勘所というか、重要な特徴量などがわかってきたので、改めてやってみようと思ったからです。
勾配ブースティングとは?
今回実装する勾配ブースティング(Gradient Boosting)について簡単に解説すると、勾配ブースティングとは機械学習のアンサンブル学習手法の一つで、多数の弱い予測モデル(多くの場合は決定木)を組み合わせて、高い予測精度を目指す手法です。具体的には、以下のステップで動作します:
- 最初にシンプルなモデルを作る
初期のモデルは、目標値(正解)をざっくり予測する簡単なもので、最初は誤差(予測のズレ)が大きいです。 - 誤差(残差)を学習する新しいモデルを追加
次に、初期モデルの誤差を分析し、誤差を補正する新しいモデルを作ります。 - これを繰り返して改善する
モデルを追加するたびに誤差が小さくなり、最終的に全体の予測精度が向上します。
この手法では、「勾配(Gradient)」という数学的な情報を利用してモデルを最適化していきます。具体的には、誤差を減らすために必要な方向を勾配で示し、それに従って次のモデルを作成していきます。
必要なpythonライブラリ
以下が主な使用ライブラリです。
- XGboost
- Beautifulsoup
- pandas
- requests
- dump
フォルダー構成
最初にフォルダー構成は以下のようになります。
各フォルダは、
- data. データ関連のフォルダー。ダウンロードファイルもここに収納
- models_clf. 分類モデル(今回のモデル)の収納フォルダー
- models_rank. ランキング学習(以前作ったモデル)の収納フォルダー
- notebook. jupyterlabで動作の確認、モデルのupdateの際に検証するためのnotebookのフォルダー
- predictions. 予測の実行ファイル、予測結果を収納するためのフォルダー
- utils. テキストデータの読み込み、データの前処理関係のファイル群。models_clf、models_rankに共通するファイルを収納。個別の前処理はmodels_clf、models_rankにそれぞれ収納
- venv. 仮想環境。
- main.py. このアプリケーションの実行ファイル
- update.py. データを更新用のpythonファイル
といった感じ。最初は適当に作っていたので、フォルダー構成などあまり気にしていなかったが、modelが増えることにより構成がグチャグチャになり自分でもどこに何があるか分からず困ったので、今後のためにも整理しました。
やっぱり整理整頓大事!!
コードやフォルダーが綺麗なのと部屋のキレイさって多分比例します。
project_rootで相対パスで実装するメリット
少し話がずれますが、今回は全てのコードを、
project_root = os.path.dirname(os.path.dirname(__file__))
と相対パスを設定しています。これまではusers/mac/~~~というような絶対パスを使っていましたが、デバイス間での共有を考えるとこちらの方が便利というのが理由です。
なので、python環境と必要ライブラリさえあれば、githubからダウンロードすれば誰でもどのpcからでも使えるようになります。
このモデルの肝|特徴量と目的変数
勾配ブースティングは教師あり学習のひとつ決定木の進化版と言えるものなので、目標値となるデータを与えなければなりません。ここがすでにランキング学習との違いで、ランキング学習は『同グループの中での優劣』を決めていたので、目標値はありませんでした。
今回は目標値を『1着かそれ以外か』に分類し1着を『0』、それ以外を『1』としてこの数値を目標値として定めます。
そして、目標値が0になる確率(1着になる確率)predict_probaを算出し、その数値を予想勝率とします。
今回使う特徴量
今回使う特徴量も基本的には前回のランキング学習で使ったものを基本的には使います。以下が全特徴量です。
[‘全国勝率1号艇’, ‘1枠パワー1号艇’, ‘トータルパワー1号艇’, ‘STパワー1号艇’, ‘全国勝率2号艇’, ‘2枠パワー2号艇’,
‘トータルパワー2号艇’, ‘STパワー2号艇’, ‘全国勝率3号艇’, ‘3枠パワー3号艇’, ‘トータルパワー3号艇’,
‘STパワー3号艇’, ‘全国勝率4号艇’, ‘4枠パワー4号艇’, ‘トータルパワー4号艇’, ‘STパワー4号艇’, ‘全国勝率5号艇’,
‘5枠パワー5号艇’, ‘トータルパワー5号艇’, ‘STパワー5号艇’, ‘全国勝率6号艇’, ‘6枠パワー6号艇’,
‘トータルパワー6号艇’, ‘STパワー6号艇’]
今回の工夫として、〇〇パワーという特徴量を過去のデータから作ったことです。
この意図は、同じ1着でも、一般戦の1着とSGレースの1着が同じ勝ちということはあり得ないことで、『レースのレベルとその着順に応じたポイントをつける』ということを目的にしています。
具体的には、
としています。ST(スタート)も同様に前処理しています。
あとは欠損値の扱いやデータタイプの加工をして、この加工済みデータをXGBoost用DMatrixにぶち込みモデルが完成します。
1号艇から6号艇のそれぞれの1着率を予想するためにターゲット(目的変数)をforループで回し、それぞれの1着率を予測するモデルを計6つ作りました。
import os
import sys
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from joblib import dump
# プロジェクトルートを取得
project_root = os.path.dirname(os.path.dirname(__file__))
data_processing_dir = os.path.join(project_root, 'utils')
sys.path.append(data_processing_dir)
from one_race import make_onerace
def train_models(axis1_data):
# データフレームのコピー
df = axis1_data.copy()
# ターゲットカラムのリスト
t_list = [f'1着{i}号艇' for i in range(1, 7)]
# 使用する特徴量のリスト
feature_columns = [
f'{col}{i}号艇' for i in range(1, 7)
for col in ['全国勝率', f'{i}枠パワー', 'トータルパワー', 'STパワー']
]
# 特徴量を数値型に変換(エラーを強制的にNaNに変換)
for col in feature_columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
# 共通パラメータ設定
params = {
'objective': 'binary:logistic', # 2クラス分類の場合
'eval_metric': 'logloss', # 損失関数
'learning_rate': 0.03, # 学習率(徐々に収束)
'max_depth': 6, # 木の深さ(適度な複雑さ)
'min_child_weight': 7, # 葉ノードの最小サンプル数(過学習防止)
'lambda': 1.0, # L2正則化項(過学習抑制)
'alpha': 0.5, # L1正則化項(過学習抑制)
'n_estimators': 1000, # 最大ラウンド数(早期停止で制御)
'verbosity': 0 # ログ出力を抑制
}
# モデルを保存するディレクトリ
model_dir = os.path.join(project_root, 'models_clf')
os.makedirs(model_dir, exist_ok=True)
# 各ターゲットに対してモデルを作成
for target in t_list:
# 予測ターゲットと特徴量の設定
X = df[feature_columns]
y = df[target].astype(int)
# データをtrain, eval, testに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train, test_size=0.1, random_state=1, stratify=y_train)
# XGBoost用DMatrixに変換
dtrain = xgb.DMatrix(X_train, label=y_train, enable_categorical=False)
deval = xgb.DMatrix(X_eval, label=y_eval, enable_categorical=False)
# モデルの学習
evals = [(dtrain, 'train'), (deval, 'eval')]
model = xgb.train(params, dtrain, num_boost_round=1000, evals=evals, early_stopping_rounds=20, verbose_eval=False)
# モデルの保存(joblib)
model_path = os.path.join(model_dir, f'model_{target}.joblib')
dump(model, model_path)
print(f"モデルを保存しました: {model_path}")
予測結果・評価指数の検証
評価指数
実際に利益が出るモデルかどうかは、じっくり検証していく必要がありますが、とりあえず現段階での評価スコアを出してみました。結果は以下の通り。
” Target Train Accuracy Eval Accuracy Test Accuracy Train Logloss \
0 1着1号艇 0.714245 0.676601 0.671304 0.563092
1 1着2号艇 0.867414 0.863665 0.865917 0.319628
2 1着3号艇 0.883273 0.877616 0.879532 0.292793
3 1着4号艇 0.898076 0.890932 0.900252 0.263082
4 1着5号艇 0.943187 0.941661 0.940950 0.167407
5 1着6号艇 0.970395 0.969562 0.966997 0.086705
Eval Logloss Test Logloss
0 0.601183 0.614619
1 0.365895 0.348584
2 0.332579 0.328191
3 0.307487 0.290815
4 0.201001 0.200110
5 0.105729 0.123852″
Accuracyは正解率で、モデルが0or1のどちらかを予想し実際に正解だった確率です。一見するとかなり良く見えますが、ボートレースの特性上、外枠(5、6号艇は特に)は圧倒的に勝ちにくいことから、ほとんどのレースを1と予想(1着にならない)と予想します。そのため1号艇以外はほぼ気にしなくていいレベル。
それよりもLogloss(損失関数)を見て過学習に陥っていないか?学習データ、学習量が不足していないかを確認することがここでは重要です。
重要特徴量
特徴量の重要度載せておきます。
重要特徴量
Feature importance for target: 1着1号艇 1枠パワー1号艇: 828.0 4枠パワー4号艇: 404.0 6枠パワー6号艇: 371.0 STパワー4号艇: 316.0 2枠パワー2号艇: 301.0 3枠パワー3号艇: 269.0 全国勝率1号艇: 259.0 STパワー2号艇: 224.0 5枠パワー5号艇: 219.0 STパワー5号艇: 214.0 全国勝率3号艇: 212.0 トータルパワー2号艇: 204.0 STパワー3号艇: 201.0 STパワー6号艇: 192.0 STパワー1号艇: 182.0 全国勝率2号艇: 174.0 全国勝率5号艇: 170.0 トータルパワー3号艇: 155.0 全国勝率4号艇: 148.0 トータルパワー1号艇: 133.0 トータルパワー4号艇: 126.0 トータルパワー5号艇: 123.0 トータルパワー6号艇: 112.0 全国勝率6号艇: 110.0 Feature importance for target: 1着2号艇 2枠パワー2号艇: 831.0 1枠パワー1号艇: 677.0 STパワー4号艇: 296.0 トータルパワー1号艇: 277.0 STパワー5号艇: 252.0 トータルパワー2号艇: 246.0 STパワー1号艇: 221.0 3枠パワー3号艇: 217.0 トータルパワー6号艇: 208.0 STパワー3号艇: 197.0 全国勝率2号艇: 178.0 トータルパワー5号艇: 174.0 STパワー2号艇: 171.0 4枠パワー4号艇: 147.0 STパワー6号艇: 147.0 6枠パワー6号艇: 133.0 5枠パワー5号艇: 117.0 全国勝率6号艇: 116.0 全国勝率1号艇: 111.0 全国勝率3号艇: 102.0 トータルパワー4号艇: 97.0 トータルパワー3号艇: 77.0 全国勝率5号艇: 67.0 全国勝率4号艇: 56.0 Feature importance for target: 1着3号艇 3枠パワー3号艇: 781.0 1枠パワー1号艇: 603.0 2枠パワー2号艇: 406.0 STパワー3号艇: 218.0 STパワー2号艇: 204.0 STパワー1号艇: 200.0 トータルパワー2号艇: 182.0 全国勝率4号艇: 178.0 全国勝率3号艇: 177.0 トータルパワー1号艇: 172.0 トータルパワー5号艇: 170.0 STパワー5号艇: 148.0 STパワー4号艇: 141.0 4枠パワー4号艇: 131.0 トータルパワー4号艇: 125.0 トータルパワー6号艇: 119.0 トータルパワー3号艇: 116.0 STパワー6号艇: 111.0 5枠パワー5号艇: 109.0 全国勝率5号艇: 105.0 6枠パワー6号艇: 103.0 全国勝率2号艇: 102.0 全国勝率1号艇: 100.0 全国勝率6号艇: 96.0 Feature importance for target: 1着4号艇 4枠パワー4号艇: 758.0 1枠パワー1号艇: 565.0 3枠パワー3号艇: 367.0 STパワー2号艇: 332.0 STパワー3号艇: 308.0 全国勝率4号艇: 302.0 2枠パワー2号艇: 280.0 STパワー4号艇: 230.0 STパワー1号艇: 204.0 トータルパワー4号艇: 166.0 トータルパワー3号艇: 163.0 全国勝率1号艇: 136.0 全国勝率2号艇: 113.0 全国勝率3号艇: 103.0 トータルパワー2号艇: 102.0 全国勝率5号艇: 102.0 全国勝率6号艇: 98.0 トータルパワー5号艇: 79.0 5枠パワー5号艇: 77.0 STパワー6号艇: 77.0 STパワー5号艇: 71.0 トータルパワー1号艇: 61.0 トータルパワー6号艇: 59.0 6枠パワー6号艇: 42.0 Feature importance for target: 1着5号艇 5枠パワー5号艇: 543.0 2枠パワー2号艇: 266.0 トータルパワー1号艇: 231.0 STパワー3号艇: 199.0 3枠パワー3号艇: 191.0 1枠パワー1号艇: 187.0 STパワー1号艇: 181.0 4枠パワー4号艇: 180.0 STパワー5号艇: 169.0 6枠パワー6号艇: 162.0 トータルパワー4号艇: 155.0 全国勝率3号艇: 148.0 STパワー4号艇: 134.0 トータルパワー2号艇: 121.0 全国勝率4号艇: 119.0 トータルパワー3号艇: 115.0 全国勝率2号艇: 110.0 トータルパワー5号艇: 96.0 全国勝率1号艇: 89.0 STパワー2号艇: 82.0 STパワー6号艇: 77.0 全国勝率5号艇: 70.0 トータルパワー6号艇: 55.0 全国勝率6号艇: 54.0 Feature importance for target: 1着6号艇 6枠パワー6号艇: 519.0 1枠パワー1号艇: 205.0 5枠パワー5号艇: 197.0 トータルパワー1号艇: 188.0 全国勝率4号艇: 161.0 全国勝率3号艇: 157.0 トータルパワー5号艇: 156.0 トータルパワー4号艇: 151.0 4枠パワー4号艇: 142.0 トータルパワー3号艇: 124.0 STパワー6号艇: 119.0 STパワー3号艇: 116.0 全国勝率5号艇: 112.0 STパワー4号艇: 111.0 トータルパワー6号艇: 111.0 STパワー2号艇: 95.0 STパワー1号艇: 87.0 2枠パワー2号艇: 71.0 3枠パワー3号艇: 61.0 全国勝率6号艇: 58.0 STパワー5号艇: 48.0 トータルパワー2号艇: 42.0 全国勝率1号艇: 27.0 全国勝率2号艇: 17.0
やはりというか、予想通りその艇番の選手自身の”枠別パワー”が重要で、2号艇から外枠の予想モデルは自身のパワーと1枠の選手のパワーが重要という結果が見て取れます。
予測結果の出力
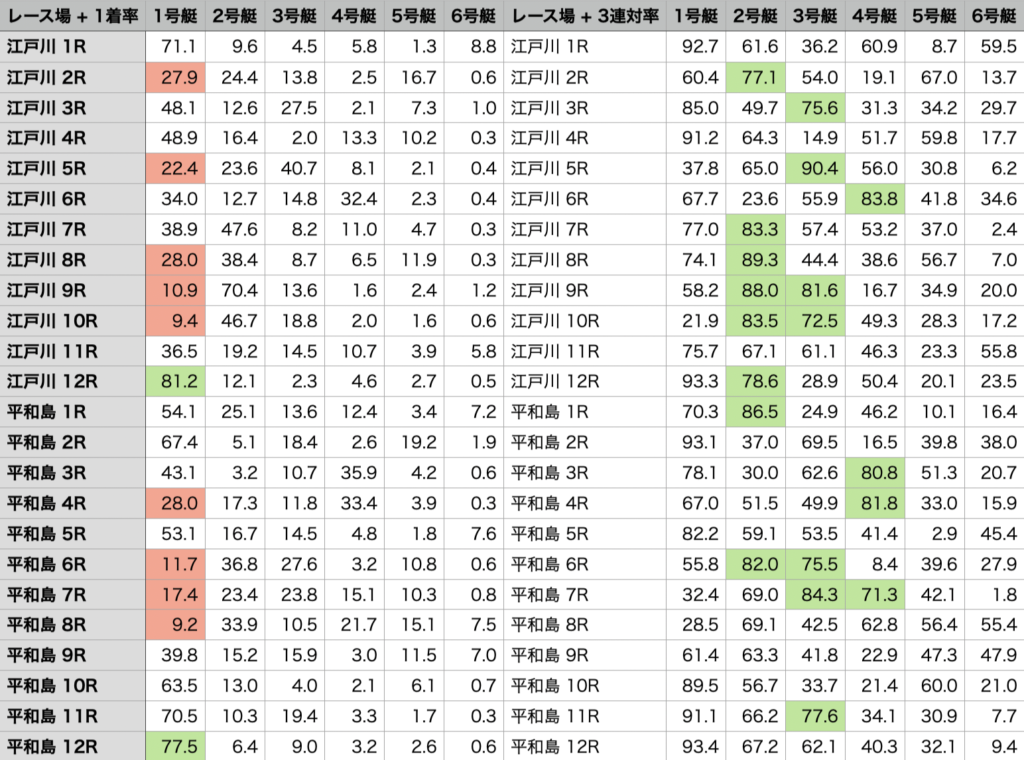
モデル構築は以上になります。最後に予測結果をcsv形式で出力して可視化できるようにします。ちなみに今回のモデルに加えて、各艇の3連対率を予想するモデルも同じ工程で作ったので、1着率と3連対率がひと目でわかるようにしました。
まとめ
概ねやりたいことは実現することができました。
的中率や回収率はまだ検証中なので、はっきりしたことは言えませんが、どうやら3連対率を予想するモデルの方が精度が高いように感じます。
これはおそらく、”パワー”という特徴量を入れたことによって、選手間の相対的な実力差が出やすいのは『3着に入るかどうか』ということで、『1着なるかどうか』というのはスリット体系やコース、展開などによって実力下位の選手でも起こりやすいというボートレース特有のルールから来てるのではないかと思います。
とりあえずはこのモデルを運用していこうと思います。







