
pythonはAI【機械学習】に強いプログラミング言語であり、pythonの学習を始めようと思った方の多くにも、『AI関連のプログラムを作りたい』『AIに携わるような仕事がしたい』といった方も多いのではないでしょうか。
今回は身近な機械学習の活用例としてボートレースの着順を予想するAIを作ってみました。
今回はPythonとXGBoostを使い、ランキング学習の手法で競艇AIを作るプロセスを解説します。Pythonが機械学習に優れている理由から、XGBoostの基礎知識、ランキング学習の使い方、実際の実装方法まで詳しく説明します。また、競艇AIの予測結果とその改善ポイントについても触れていきます。競艇予測に挑戦したい方や、AIの実装を学びたい方の参考になれば幸いです。
PythonがAI開発・機械学習に向いている理由とは?
まず、なぜPythonがAI開発においてこれほどまでに人気なのかを見てみましょう。
- シンプルで分かりやすい文法
Pythonのコードは、初心者にも理解しやすいシンプルな構造を持ちます。これは複雑な計算やアルゴリズムを扱うAI開発において特に有用で、可読性が高く、開発の効率を上げる要因です。 - 豊富なライブラリとコミュニティ
AI開発におけるPythonの人気の理由の一つに、膨大なライブラリの充実があります。例えば、機械学習やデータ処理のためのNumPy、Pandas、機械学習モデルの構築を容易にするscikit-learn、さらには今回使用するXGBoostなど、プロジェクトの目的に合ったライブラリを利用できます。これにより開発効率が大幅に向上し、膨大な量のデータを素早く処理できるのです。 - 競艇AIの実装でPythonが役立つ理由
Pythonはデータの読み込みや前処理が簡単に行え、複雑なAIモデルのトレーニングも手軽に実装できます。今回の競艇AIでは、順位予測のためにXGBoostを使用しますが、このライブラリはPythonとの相性が良く、特にランキング学習において効率的に動作するため最適です。
XGBoostとランキング学習とは何か?
XGBoostは、勾配ブースティングアルゴリズムに基づいた機械学習ライブラリで、特に分類問題や回帰問題で高精度の予測ができるため、データサイエンスの分野で幅広く利用されています。
- XGBoostの基本
XGBoost(Extreme Gradient Boosting)は、複数の弱いモデル(一般的には決定木)を結合して高い精度を達成する「ブースティング」手法の一つです。各モデルは前のモデルの誤差を補うように学習し、モデル全体の精度を向上させることが特徴です。高速な計算速度やパラメータの柔軟さがXGBoostの強みで、AI予測精度が求められる競艇AIには最適です。 - 決定木・ランダムフォレストとの違い
決定木は1つの分岐ツリーを使って予測を行いますが、単独では精度が低いことが多いです。一方でランダムフォレストは、多数の決定木を用意し、予測結果を投票(多数決)で決定する「バギング」手法です。しかし、ランダムフォレストは各ツリーが独立して学習するため、精度向上には限界があります。これに対しXGBoostは、誤差を段階的に改善する「ブースティング」によって、より精密な予測を実現します。 - ランキング学習とは?
ランキング学習(Learning to Rank)は、従来の分類や回帰とは異なり、アイテムの順序を学習する手法です。競艇の順位予測において、最も上位にくる艇を高い精度で予測するために適しています。ランキング学習では、各艇の順位の優劣を学習するため、レース結果を学習データとして利用し、順位付けに特化したモデルを構築します。
いざ実装!
今回、モデルを実装するにあたり2024年9月・10月のデータを使って実装していきます。
まずはボートレース公式HPが公開しているレース結果と番組表をダウンロードし、データをcsvとして保存します(ここは本題ではないので割愛)。
次に、以下のように不要なデータ、学習に不向きと思われるデータを削除していきます。このランキング学習の肝は、『同一レースの中で、誰が勝つか予想しようぜ』というものなので、一つのデータフレームの中でクエリ(今回は”id”)を渡し、どの行とどの行が同じレースなのかを識別させます。
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
result_df = pd.read_csv("data_master/result_csv/data_result202410.csv")
personal_df = pd.read_csv("data_master/personal_csv/personal_data.csv")
joindf=pd.merge(result_df,personal_df,on="選手登番")
# 着順にNaNが含まれるレースIDを取得
nan_ids = joindf[joindf['着順'].isna()]['id'].unique()
# NaNが含まれるレースIDと一致する行をすべて削除
result_df = joindf[~joindf['id'].isin(nan_ids)]
# 各レースのidごとの出場選手数をカウント
race_counts = result_df['id'].value_counts()
# 出場選手数が6人のidのみ取得
valid_ids = race_counts[race_counts == 6].index
# 有効なidを持つ行のみを抽出
result_df = result_df[result_df['id'].isin(valid_ids)]正直、機械学習は実装するだけであれば、難しくありません。むしろデータの前処理と、実装後の評価と改善が技術が問われるところです。
今回は非常にシンプルに良くある特徴量を使ってモデルを作ります。以下が元のデータフレームでここから必要な特徴量とクエリを取得していきます。
df1=result_df[["着順","艇番","全国勝率","展示","平均ST順位","id",'1枠1着率', '1枠2連対率', '1枠3連対率', '2枠1着率', '2枠2連対率', '2枠3連対率', '3枠1着率',
'3枠2連対率', '3枠3連対率', '4枠1着率', '4枠2連対率', '4枠3連対率', '5枠1着率', '5枠2連対率',
'5枠3連対率', '6枠1着率', '6枠2連対率', '6枠3連対率']]そして、このデータフレームをidごとにトレーニング用とテスト用に分割し、使う特徴量を指定すれば、あとはDMatrixに変換し、各パラメーターを設定すれば、xgb.train()でモデルの学習は完了です。
# データフレームをレースIDごとに分割
unique_race_ids = df1['id'].unique()
train_ids, test_ids = train_test_split(unique_race_ids, test_size=0.2, random_state=42)
# トレーニング用・テスト用のデータを準備
train_data = df1[df1['id'].isin(train_ids)]
test_data = df1[df1['id'].isin(test_ids)]
# 特徴量とラベルを抽出
X_train = np.vstack(train_data[["艇番","全国勝率","平均ST順位", '1枠3連対率', '2枠3連対率', '3枠3連対率', '4枠3連対率',
'5枠3連対率', '6枠3連対率']].values)
y_train = train_data[['着順']]
X_test = np.vstack(test_data[["艇番","全国勝率","平均ST順位", '1枠3連対率', '2枠3連対率', '3枠3連対率', '4枠3連対率',
'5枠3連対率', '6枠3連対率']].values)
y_test = test_data[['着順']]
# レースごとのグループ数を設定
groups_train = train_data['id'].value_counts(sort=False).values
groups_test = test_data['id'].value_counts(sort=False).values
# トレーニングデータとテストデータをDMatrixに変換
dtrain = xgb.DMatrix(X_train, label=y_train)
dtrain.set_group(groups_train) # グループ数を設定
dtest = xgb.DMatrix(X_test, label=y_test)
dtest.set_group(groups_test)
# ランキング用のパラメータ設定
params = {
'objective': 'rank:pairwise', # 順位学習
'eta': 0.01,
'gamma': 1.0,
'min_child_weight': 0.1,
'max_depth': 6
}
# モデルの学習
rank_model = xgb.train(params, dtrain, num_boost_round=100)
# テストデータで予測
predictions = rank_model.predict(dtest)シュミレーション結果
一応、自分なりには色々パラメータを変えてみたり、特徴量を追加したりしたのですが、大きな向上が見込めなかったので、ひとまずこのモデルの評価をしていきたいと思います。数学や統計学の知識がもっとあれば、さらなる向上が見込めそうですが、残念ながら私には・・・
さて、まずこのランキング学習のモデルの評価のひとつにNDCGというのがあります。
NDCG(Normalized Discounted Cumulative Gain)は、ランキング精度を評価するための指標で、特に情報検索システムや推薦システムの分野で使用されることが多い評価指標です。NDCGは、検索結果や推薦リストの中で、関連性の高いアイテムが上位に表示されているかどうかを評価するために使われます。
評価値は0~1で表され1に近ければ精度が高いと言えます。
test_dataに予測値と予測順位をつけNDCGを見てみます。
test_data['predicted_score'] = predictions # 予測スコアを追加
test_data['predicted_rank'] = (
test_data.groupby('id')['predicted_score']
.rank(method='first', ascending=True)
)
#predicted_dfの作成
predicted_df=test_data[["id","艇番","predicted_score","着順"]]
from sklearn.metrics import ndcg_score
def mean_ndcg(df):
ndcg_scores = []
for race_id, group in df.groupby('id'):
y_true = group['着順'].apply(lambda x: 1 if x <= 3 else 0).values
y_scores = -group['predicted_score'].values
ndcg = ndcg_score([y_true], [y_scores])
ndcg_scores.append(ndcg)
return np.mean(ndcg_scores)
ndcg_score = mean_ndcg(predicted_df)
print(f"NDCG: {ndcg_score:.2f}")結果は0.90というものでした。ここだけを見るとモデルの精度はかなり高いと言えそうです。
回収率・的中率
しかし、今回のボートレース予想AIにおいて重要なのは、『的中率』『回収率』になります。
今回のランキング学習は分類問題などとは違い、1号艇の1着率何%というようには評価を出しません。あくまで、同一レースの中での横の比較『どちらが上位着にくるか』というのを予測結果として出します。
なので、
今回の検証方法として、『上位3着と予想した3艇をボックスで買う』と仮定して検証します。
果たして結果は・・・・
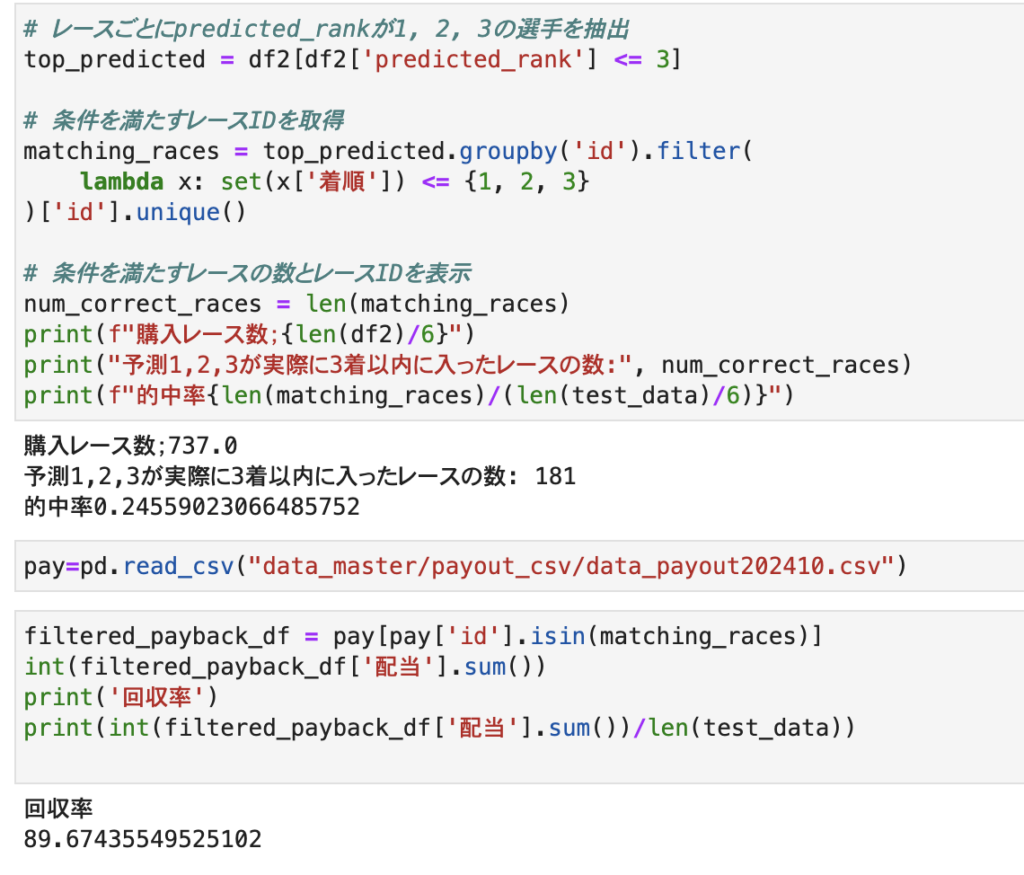
- 購入レース数:737レース
- 的中レース数:181レース
- 的中率:24.5%
- 回収率:89.6%
という結果になりました。控除率が25%の競艇でなので、回収率75%というのが標準と言えます。その中で89%の回収率というのは結構健闘していると言えるのではないでしょうか。
改善点・次回に向けて
検証結果には概ね納得していますが、さらなる向上も狙うことができます。今回使ったデータは2ヶ月分のみ、特徴量に特に工夫なしというものだったので、データ量を増やし、特徴量エンジニアリング等でさらに向上を狙える可能性もあります。具体的には他に、
- 特徴量の見直し
モデルの精度向上のため、さらに有用な特徴量を追加することや、不要な特徴を減らす方法について検討します。例えば、天候や水面の状況などを追加し、より精密な予測が可能になるかもしれません。 - パラメータのチューニング
予測精度を向上させるため、XGBoostのハイパーパラメータ(木の深さ、学習率など)の再調整を行い、モデルの過学習や未学習を防ぎます。
などがあります。
しかし、NDCGが0.9と高くモデルとしては現時点でも悪くないということを考えると、オッズから期待値を分析したり、適した買い方の分析をする方が回収率向上には効果がありそうな気がします。
まとめ
PythonとXGBoostを活用した競艇予測AIの紹介をしてきました。私自身、ランキング学習で実装するのが初めてだったので、新しい発見もあり面白かったです。
今回のモデルの実装には、データ取得からモデルの完成、検証まで2日で完了しました。これほど短期間でできるのもpythonの充実したライブラリがあることが要因で、改めてpythonの機械学習に対する強さを感じることとなりました。
ひとまず、完成ではありますが、さらに精度を向上させたり、GUIで動作させるなど使いやすさを向上させたりとちょこちょこいじっていきます。
また、進展があったらこのブログで進捗を報告していこうと思うので、面白かったという方は、ぜひお気に入り登録して次の記事を楽しみにしていてね。
それではまた。







